MapReduce Terminologies
Map Reduce is the data processing component of Hadoop. Map-Reduce programs transform lists of input data elements into lists of output data elements. A Map-Reduce program will do this twice, using two different list processing idioms
- Map
- Reduce
In between Map and Reduce, there is small phase called Shuffle and Sort. Let’s understand basic terminologies used in Map Reduce
Job
1. A “complete program” – an execution of a Mapper and Reducer across a data set.
2. Job is an execution of 2 processing layers i.e. mapper and reducer. A MapReduce job is a work that the client wants to be performed.
3. It consists of the input data, the MapReduce Program, and configuration info.
4. So, client needs to submit input data, he needs to write Map Reduce program and set the configuration info (These were provided during Hadoop setup in the configuration file and also we specify some configurations in our program itself which will be specific to our map reduce job).
Task
1. An execution of a Mapper or a Reducer on a slice of data. It is also called Task-In-Progress (TIP).
Task means processing of data is in progress either on mapper or reducer.
2. Master divides the work into task and schedules it on the slaves.
Task Attempt
1. A particular instance of an attempt to execute a task on a node.
2. There is a possibility that anytime any machine can go down. For example, while processing data if any node goes down, framework reschedules the task to some other node. This rescheduling of the task cannot be infinite. There is an upper limit for that as well. The default value of task attempt is 4. If a task (Mapper or reducer) fails 4 times, then the job is considered as a failed job. For high priority job or huge job, the value of this task attempt can also be increased.
Map Abstraction
Let us understand the abstract form of Map, the first phase of MapReduce paradigm, what is a map/mapper, what is the input to the mapper, how it processes the data, what is output from the mapper? The map takes key/value pair as input. Whether data is in structured or unstructured format, framework converts the incoming data into key and value.
- Key is a reference to the input value.
- Value is the data set on which to operate.
Map Processing
- A function defined by user – user can write custom business logic according to his need to process the data.
- Applies to every value in value input.
Map produces a new list of key/value pairs
- An output of Map is called intermediate output.
- It can be the different type from input pair.
- An output of map is stored on the local disk from where it is shuffled to reduce nodes.
Reduce Abstraction
Now let’s discuss the second phase of MapReduce – Reducer, what is the input to the reducer, what work reducer does, where reducer writes output?
Reduce takes intermediate Key / Value pairs as input and processes the output of the mapper. Usually, in the reducer, we do aggregation or summation sort of computation.
- Input given to reducer is generated by Map (intermediate output)
- Key / Value pairs provided to reduce are sorted by key
Reduce processing
- A function defined by user – Here also user can write custom business logic and get the final output.
- Iterator supplies the values for a given key to the Reduce function.
Reduce produces a final list of key/value pairs:
- An output of Reduce is called Final output.
- It can be a different type from input pair.
- An output of Reduce is stored in HDFS.
How Map and Reduce Work Together?
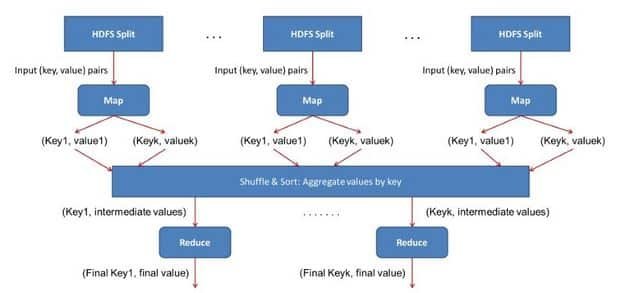
As shown in above figure Input data given to mapper is processed through user defined function written at mapper. All the required complex business logic is implemented at the mapper level so that heavy processing is done by the mapper in parallel as the number of mappers is much more than the number of reducers. Mapper generates an output which is intermediate data and this output goes as input to reducer.
This intermediate result is then processed by user defined function written at reducer and final output is generated. Usually, in reducer very light processing is done. This final output is stored in HDFS and replication is done as usual.