Introduction and Need
Data is everywhere. There is no way to measure the exact total volume of data stored electronically but it should be in zettabytes (A zettabyte is 1 billion terabytes). So, we have a lot of data and we are struggling to store and analyze it. Now let’s try to figure out what is wrong with dealing with such an enormous volume of data. The answer is same what’s wrong in data from PC to portable drives: Speed. Over the years the storage capacities of hard drives have increased like anything but the rate at which data can be read from drives have not kept up and writing is even slower.
Solution
To read from multiple disks at a time. For instance, if we have to store 100 GB of data and we have 100 drives with 100 GB storage space, then it would be faster to read data from 100 drives, each holding 1 GB of data than a single drive holding 100 GB of data.
Problem with solution
1. When using a large number of hardware pieces (hard disks) there is high possibility that one or two might fail.
2. Correctly combining the data from different hard disks.
MapReduce provides a programming model that abstracts the problem from disk reads and writes, transforming it into computation over sets of keys and values. So, MapReduce is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks.
Introduction to MapReduce
1. MapReduce is the processing layer of Hadoop. It is the heart of Hadoop.
2. MapReduce is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks.
3. We need to put business logic in the way MapReduce works and rest things will be taken care by the framework. Work (complete job) which is submitted by the user to master is divided into small works (tasks) and assigned to slaves.
4. MapReduce programs are written in a particular style influenced by functional programming constructs, specifically idioms for processing lists of data. Here in MapReduce, we get inputs from a list and it converts it into output which is again a list.
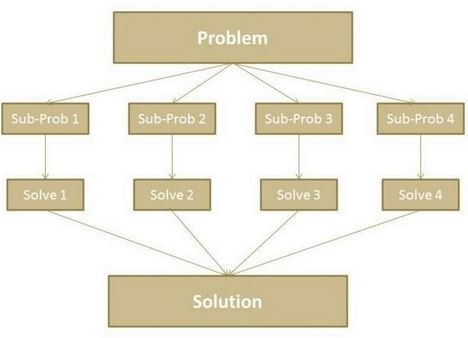
MapReduce – High level Understanding
1. Map-Reduce divides the work into small parts, each of which can be done in parallel on the cluster of servers.
2. A problem is divided into a large number of smaller problems each of which is processed to give individual outputs. These individual outputs are further processed to give final output.
3. Hadoop Map-Reduce is scalable and can also be used across many computers.
4. Many small machines can be used to process jobs that could not be processed by a large machine.