Kafka Producers
In this tutorial, we are going to discuss Apache Kafka Producers and Message keys. Once a topic has been created with Kafka, the next step is to send data to the topic. This is where Kafka Producers come in.
What are Kafka Producers?
Applications that send data into topics are known as Kafka producers. Applications typically integrate a Kafka client library to write to Apache Kafka. Excellent client libraries exist for almost all programming languages that are popular today including Python, Java, Go, and others.
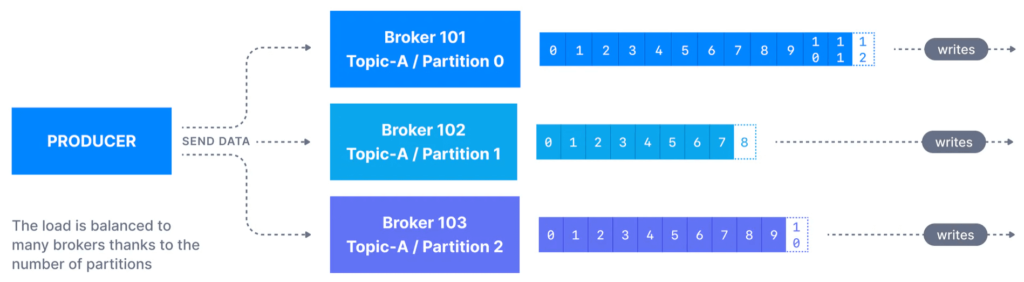
So the producers are going to write data to the topic, partitions. So remember, we have partition 0 for my topic named topic A, then Partition 1, Partition 2, and the writes happen sequentially with data Offsets.
And then your producer is right before that is going to send data into Kafka topic, partitions. So the producers know in advance to which partition they write to, and then which Kafka broker, which is a Kafka server has it. So that means that the producers know in advance in which partition the message is going to be written. Some people think that Kafka decides at the end, the server to which partition data get written, this is wrong.
The producer decides in advance which partition to write to and we’ll see how. And then in the case of A, the Kafka server that has a partition as a failure, the producers know how to automatically recover. So there’s a lot of behind-the-scenes magic. That we’ll explain over time what happens within Kafka. So we have load balancing in this case because your producers, they’re going to send data across all partitions based on some mechanism, and this is why Kafka scales, its because we have many partitions within a topic and each partition is going to receive messages and each partition is going to receive messages from one or more producers.
Producers: Message Keys
So now producers have message keys in the message. So the message itself container data, but then we can add a key, and it’s optional. And the key can be anything you want. It could be a string, a number, a binary, etc. So you have 2 cases.
In this example, I’ve taken a producer that is writing to the topic with two partitions. So if the ket is null, then the data is going to be sent round-robin. So that means that it’s going to be sent to partition 0 then partition 1, then partition 2, and so on, and this is how we get load balancing.
Key=null means that the key was not provided in the producer message. But if the key is not null, that means that the key has some value. It could be again a string, a number, a binary, whatever you want. And the Kafka producers have a very important property, the is that all the messages that share the same key will always end up being written to the same partition using hashing strategy.
This hashing property is very important in Apache Kafka. So when we specify a key, this is when we need message ordering for a specific field. So remember our example with trucks beforehand. We had trucks and it would be good for us to get the position of each individual truck in order.
So in that case, I’m going to provide truck ID as the key to my messages. Why? Well, then, for example, truck ID 123, which is an ID of one of my trucks is going to be always sent to partition 0, and I can read data in order for that one truck. And truck ID 234 is always also to be sent to partition 0 and which key ends up in which partition is made. Thanks to the hashing technique. And then, for example, another truck ID, for example, 345 or 456 will always end up in partition 1 of your topic A.

Kafka Message Anatomy
So the key is the part of a Kafka message. And here is what a Kafka message looks like when it’s created by the producer.
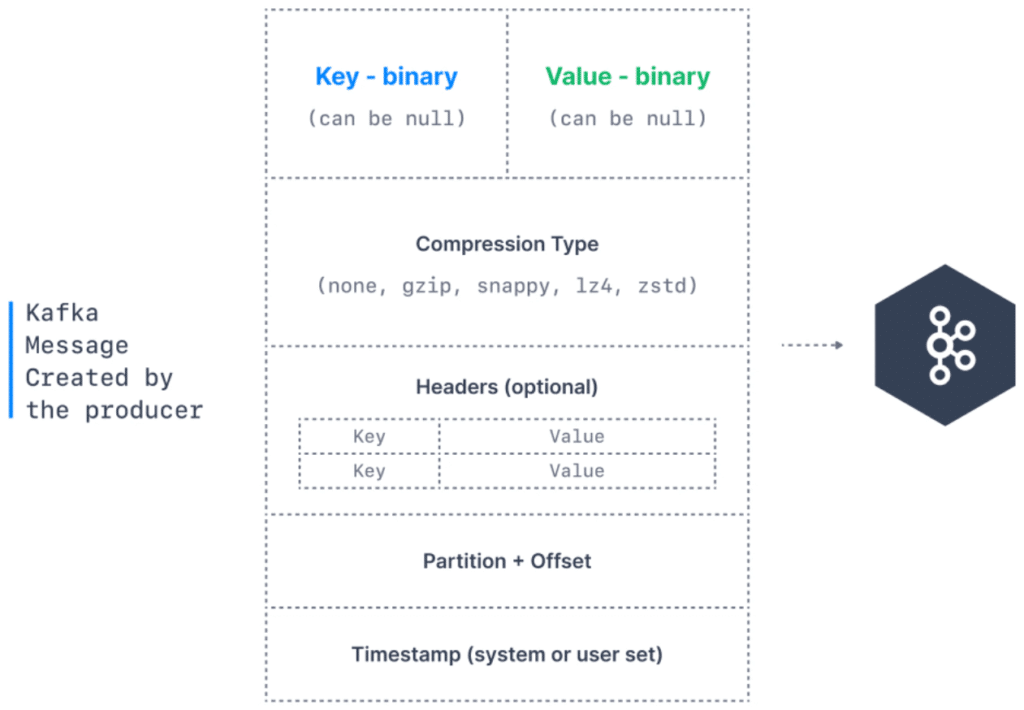
So we have the key and it can be null as we have seen and it’s in binary format. Then we have the value, which is our message content. It can be null as well, but usually is not, and it contains the vale of your message. Then we can add compression onto our messages.
So do we want them to be smaller? If so, we can specify a compression mechanism. For example, gzip, snappy, lz4 or zstd. Then we can also add headers to our message, which are optional list of key value pairs. Then we have the partition that the message is going to be sent to as well as its Offsets. And then finally, a timestamp that is either set by the system or by the user. And this is what a Kafka message is, and then it gets sent into Apache Kafka for storage. So how do these messages get created?
Kafka Message Serializers
So we have what’s called a Kafka message serializer. In many programming languages, the key and value are represented as objects, which greatly increases the code readability. Apache Kafka is a very good technology, And what makes it good is that it only accepts series of bytes as an input from producers, and it will send bytes as an output to consumers. But when we construct messages, they’re not bytes. So we are going to perform message serialization. And doing serialization means that we are going to transform your data, your objects into bytes, and it’s not that complicated, I will show you right now.

And then these serializers are going to be used only on the value and the key. So say for example, we have a key object. So it’s going to be the truck ID, so 123, and then the value is just going to be a string “hello world”. So these are not bytes just yet. They are objects within our programming language. But then we’re going to specify the key Serializer to be an integer serializer. And what’s going to happen is that Kafka producer is smart enough to transform that key object 123 through the serializer into a series of bytes, which is going to give us a binary representation of that key.
And then for the value object, we’re going to specify a string serializer, as you see the value and the ket serializaer in this instance are different. And so that means that it’s going to be smart enough to transform the string, hello world into a series of bytes for our value. And now that we have the key and the value as binary representations, that message is not ready to be sent into Apache kafka. So Kafka producers come with common serializers that help you do this transformation.
So we have string, including JSON representation of the String, Integer, Floats, Avro, Protobuf and so on. We can find a lot of message serializer out there.
Kafka Message Key Hashing
So just for the curious about those who want to understand how the message keys are hashed, and this is more advanced. Just for those who are curious. There is something called a Kafka partitioner, which is code logic that will take a record, a message, and determine to which partition to send it to. So when we do a send, the producer partitioner logic is going to look at the record and then assign it to a partition, for example, partition 1. And then it gets sent by the producer into Apache Kafka.

And the process of key hashing is used to determine the mapping of a key to a partition, and in the default kafka partitioner, then the kets are going to be hashed using murmur2 algorithm and there is a formula right here.
targetPartition = Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1)This is just to stress the fact that producers are the one who choose where the message is going to end up. It is possible to override the default partitioner via the producer property partitioner.class, although it is not advisable unless you know what you are doing.