Kafka Consumer Groups
In this tutorial, we are going to discuss Kafka Consumer groups and Offsets. We have seen that consumers can consume data from Kafka topics partitions individually, but for horizontal scalability purposes it is recommended to consume Kafka topics as a group.
So when we have Kafka and we want to scale we’re going to have many consumers in an application and they’re going to read data as a group and it’s called a consumer group.
So let’s take an example of a Kafka topic with 5 partitions, and then we have a consumer group that is called consumer group application, it’s just a name I give it. And then that consumer group has 3 consumers 1,2 and 3.

Each consumer within the group if they belong to the same group is going to be reading from exclusive partitions. That means that my consumer 1 is going to read from partition 0, and maybe partition 1. My consumer 2 is going to read from partitions 2 and 3 and finally, my consumer 3 is going to read from partition 4.
So as we can see consumers 1, 2, and 3 are sharing the reads from all the partitions and they read all from a distinct partition. This way, a group is reading the Kafka topic as a whole. So what if you have too many consumers in your consumer group, more than partitions?
So let’s take an example of a topic A, with partitions 0, 1, and 2, and then my consumer group application has consumers 1, 2, and 3. So in this case, we know that the mapping is simple. We have each consumer reading from one partition and then if we add another consumer into this consumer group and we can, it’s possible then that Consumer 4 is going to be inactive.
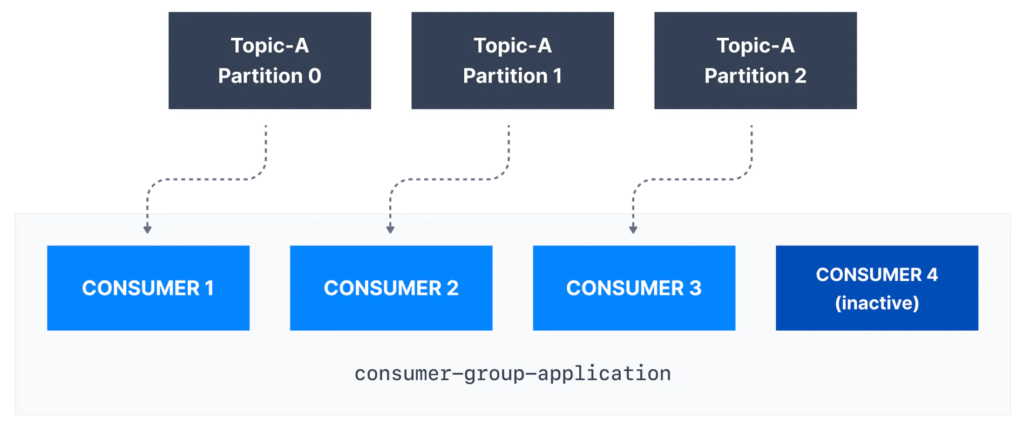
That means that it’s just going to be stand by consumer, and it’s not going to read from any topic partitions and that’s okay, but you need to know that it’s normal. That Consumer 4 is not going to help Consumer 1 to read from Partition 0, no, it’s going to stay inactive. And also you can have multiple consumer groups on one topic. So it is completely acceptable to have multiple Kafka consumer groups on the same topic and let’s take an example.
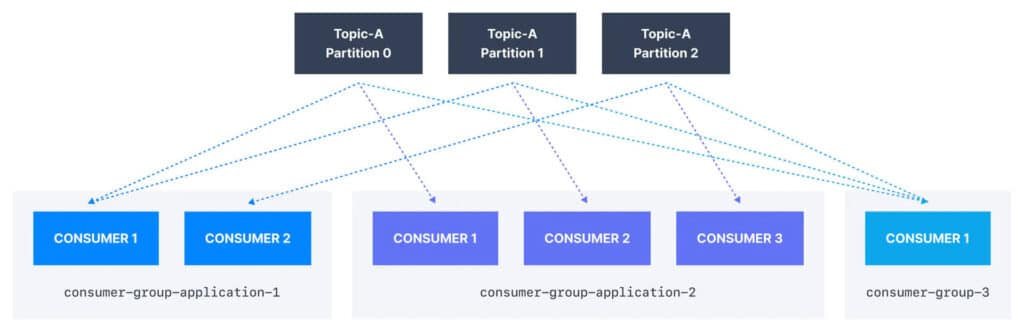
So we go back to our topic with 3 partitions and then we have our first consumer group that I’ve named consumer-group-application-1 and it has 2 consumers. Now they’re going to share their reads from our topic partitions. So consumer 1 is going to read from two partitions, and consumer 2, just from one and that’s fine.
Then we have a second consumer group application, and this one will have 3 consumers, and each of them is going to be reading from a distinct partition. And then finally, if we have a consumer group 3 with just 1 consumer, that consumer is going to be reading from all topic partitions.
So as we can see, it’s fine to have multiple consumer groups on the topic, then each partition will have multiple readers, right? But within a consumer group, only one consumer is going to be assigned to one partition. And so why would you have multiple Kafka consumer groups?
Well, if you go back to the example of the truck that I gave you, we had a location service and a notification service reading from the same data streams of truck GPS. Well, that means that we’re going to have one consumer group per service. So one consumer group will be for the location service, and another consumer group will be for the notification service.
Now to create distinct consumer groups we’re going to use the consumer property named group.id to give a name to a consumer group, and then consumers will know in which group they belong. And these groups they’re even more powerful than what we think. So in this group, we can define consumer offsets, what are they?
Kafka Consumer Offsets
Kafka is going to store the offsets at which a consumer group has been reading. And these offsets are going to be in a Kafka topic named consumers offsets with underscores in the beginning because it’s an internal Kafka topic.
In simple words, Kafka brokers use an internal topic named __consumer_offsets that keeps track of what messages a given consumer group last successfully processed.
So let’s take an example and we will understand why consumer offsets are so important.

So we have this topic, and what I represented right here vertically is an offset, so we’ve been writing a lot on this topic and now we have number 4258, all the way up.
So we have a consumer from within the consumer group and is going to commit offsets once in a while. And when the offsets are committed, this is going to allow the consumer to keep on reading from the offsets onwards.
And so the idea is that when a consumer is done processing the data that is received from Apache Kafka, it should once in a while commit the offsets and tell the Kafka brokers to write to the consumer offset topic, and by committing the offsets we’re going to be able to tell the Kafka broker how far we’ve been successfully reading into the Kafka topic. So this is why you do it once in a while.
While you do this well, because if your consumer dies then comes back and then is going to be able to read back from where it left it off. Thanks to the committed consumer offsets, Kafka is going to say, hey in this partition 2, it seems you have been reading up to these offsets for 4262.
So we’re going to be able to have some mechanism to replay data from where we have crashed or failed. So that means that we have different delivery semantics for consumers, and we’ll explore those in detail later on in these tutorials.
Delivery semantics for consumers
But by default, the Java Consumers will automatically commit offsets in at least once mode. But if you choose to commit manually, you have 3 delivery semantics and I will explain those in detail later. So we have at least once which means that the offsets are going to be committed right after the message is processed and in case the processing goes wrong, then there’s a chance we are going to read that message again.
So that means that we can have duplicate processing of messages in this setting, and so we need to make sure that our processing is idempotent. That means that when you process again the messages it will not impact your system.
The second option is to go at most once and the effect of this is that we commit offsets as soon as the consumers receive messages but then if the processing goes wrong then some messages are going to be lost because there won’t be read again because we have committed offsets sooner than actually processing the message. So that means that we see messages at most once.
The next option is exactly once where we want to process messages just once. So when we do Kafka to Kafka workflow that means when we read from a topic and then write back to topic as a result we can use the transactional API, which is very easy to use if you use the Kafka streams API as well.
In practice, at least once with idempotent processing is the most desirable and widely implemented mechanism for Kafka consumers.