HDFS High Availability
Before Hadoop 2.0.0, the NameNode was a single point of failure in an HDFS cluster. Each cluster had a single NameNode, and if NameNode fails, the cluster as a whole would be out services.
The concept of High Availability cluster was introduced in Hadoop 2.x to solve the single point of failure problem in Hadoop 1.x. HDFS Architecture follows Master/Slave Topology where NameNode acts as a master daemon and is responsible for managing other slave nodes called DataNodes. This single Master Daemon or NameNode becomes a bottleneck. Although, using Secondary NameNode we can prevent us from data loss and offloading some of the burden of the NameNode but, it did not solve the availability issue of the NameNode.
NameNode Availability
If you consider the standard configuration of HDFS cluster, the NameNode becomes a single point of failure. It happens because the moment the NameNode becomes unavailable, the whole cluster becomes unavailable until someone restarts the NameNode or brings a new one. The reasons for unavailability of NameNode can be
1. Planned maintenance activities like software or hardware upgrades on the Namenode would result in downtime of the Hadoop cluster.
2. If any unplanned event triggers, like machine crash, then cluster would be Unavailable unless an operator restarted the new namenode.
3. In either of the above cases, we have a downtime where we are not able to use the HDFS cluster which becomes a challenge.
HDFS HA Architecture
The HA architecture solved this problem of NameNode availability by allowing us to have two NameNodes in an active/passive configuration. So, we have two running NameNodes at the same time in a High Availability cluster
- Active NameNode
- Standby/Passive NameNode.
Hadoop 2.0 overcomes this single point of failure by providing support for many NameNode. HDFS NameNode High Availability architecture provides the option of running two redundant NameNodes in the same cluster in an active/passive configuration with a hot standby.
Active NameNode – It handles all client operations in the cluster.
Passive NameNode – It is a standby namenode, which has similar data as active NameNode. It acts as a slave, maintains enough state to provide a fast failover, if necessary.
If Active NameNode fails, then passive NameNode takes all the responsibility of active node and cluster continues to work. There are two issues in maintaining consistency in the HDFS High Availability cluster
1. Active and Standby NameNode should always be in sync with each other, i.e. They should have the same metadata. This will allow us to restore the Hadoop cluster to the same namespace state where it got crashed and therefore, will provide us to have fast failover.
2. There should be only one active NameNode at a time because two active NameNode will lead to corruption of the data. This kind of scenario is termed as a split-brain scenario where a cluster gets divided into smaller cluster, each one believing that it is the only active cluster. To avoid such scenarios fencing is done. Fencing is a process of ensuring that only one NameNode remains active at a particular time.
Implementation of HA Architecture
In HDFS NameNode High Availability Architecture, 2 NameNodes running at the same time. We can Implement the Active and Standby NameNode configuration in following 2 ways
- Using Quorum Journal Nodes
- Using Shared Storage.
1. Using Quorum Journal Nodes
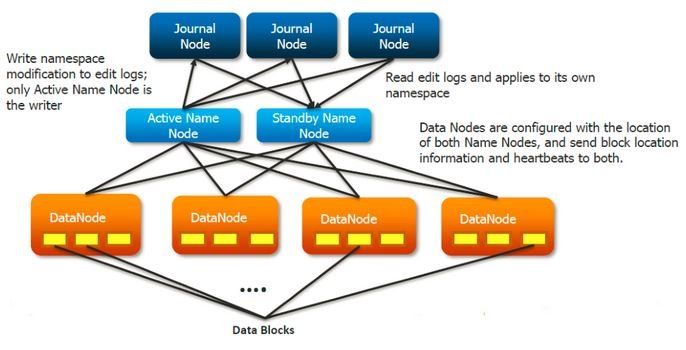
1. The standby NameNode and the active NameNode keep in sync with each other through a separate group of nodes or daemons -called JournalNodes. The JournalNodes follows the ring topology where the nodes are connected to each other to form a ring. The JournalNode serves the request coming to it and copies the information into other nodes in the ring.This provides fault tolerance in case of JournalNode failure.
2. The active NameNode is responsible for updating the EditLogs (metadata information) present in the JournalNodes.
3. The Standby NameNode reads the changes made to the EditLogs in the JournalNode and applies it to its own namespace in a constant manner.
4. During failover, the StandbyNode makes sure that it has updated its meta data information from the JournalNodes before becoming the new Active NameNode. This makes the current namespace state synchronized with the state before failover.
5. The IP Addresses of both the NameNodes are available to all the DataNodes and they send their heartbeats and block location information to both the NameNode. This provides a fast failover (less down time) as the StandbyNode has an updated information about the block location in the cluster.
Fencing of NameNode
For the correct operation of an HA cluster, only one of the NameNodes should active at a time. Otherwise, the namespace state would deviate between the two NameNodes. So, fencing is a process to ensure this property in a cluster.
1. The journal nodes perform this fencing by allowing only one NameNodeto be the writer at a time.
2. The standby NameNode takes the responsibility of writing to the journal nodes and prohibit any other NameNode to remain active.
3. Finally, the new active NameNode can perform its activities.
2. Using Shared Storage
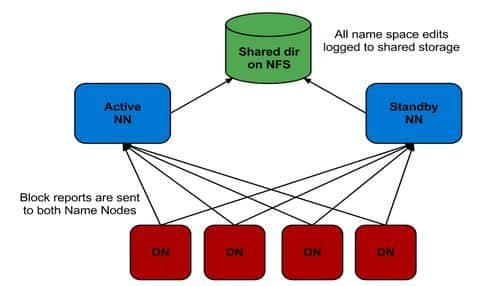
1. The StandbyNode and the active NameNode keep in sync with each other by using a shared storage device. The active NameNode logs the record of any modification done in its namespace to an EditLog present in this shared storage. The StandbyNode reads the changes made to the EditLogs in this shared storage and applies it to its own namespace.
2. Now, in case of failover, the StandbyNode updates its metadata information using the EditLogs in the shared storage at first. Then, it takes the responsibility of the Active NameNode. This makes the current namespace state synchronized with the state before failover.
3. The administrator must configure at least one fencing method to avoid a split-brain scenario.
4. The system may employ a range of fencing mechanisms. It may include killing of the NameNode’s process and revoking its access to the shared storage directory.
5. As a last resort, we can fence the previously active NameNode with a technique known as STONITH, or “shoot the other node in the head”. STONITH uses a specialized power distribution unit to forcibly power down the NameNode machine.
Automatic Failover
Failover is a procedure by which a system automatically transfers control to secondary system when it detects a fault or failure. There are two types of failover:
Graceful Failover: In this case, we manually initiate the failover for routine maintenance (planned event).
Automatic Failover: In this case, the failover is initiated automatically in case of NameNode failure (unplanned event).
Apache Zookeeper is a service that provides the automatic failover capability in HDFS High Availabilty cluster. It maintains small amounts of coordination data, informs clients of changes in that data, and monitors clients for failures. Zookeeper maintains a session with the NameNodes. In case of failure, the session will expire and the Zookeeper will inform other NameNodes to initiate the failover process. In case of NameNode failure, other passive NameNode can take a lock in Zookeeper stating that it wants to become the next Active NameNode.
The ZookeerFailoverController (ZKFC) is a Zookeeper client that also monitors and manages the NameNode status. Each of the NameNode runs a ZKFC also. ZKFC is responsible for monitoring the health of the NameNodes periodically.