Introduction
With Hadoop, we can perform only batch processing, and data will be accessed only in a sequential manner. That means one has to search the entire dataset even for the simplest of jobs. A huge dataset when processed results in another huge data set, which should also be processed sequentially. At this point, a new solution is needed to access any point of data in a single unit of time (random access).
Hadoop Random Access Databases
Applications like HBase, Cassandra, couchDB, Dynamo, and MongoDB are some of the databases that store huge amounts of data and access the data in a random manner.
What is HBase
HBase is an open source, distributed column-oriented database built on top of the Hadoop file system (HDFS), developed by Apache Software foundation. Initially, it was Google Big Table, afterwards it was re-named as HBase to provide quick random access to huge amounts of structured data. and is primarily written in Java. HBase can store massive amounts of data from terabytes to petabytes.
HBase is a part of the Hadoop ecosystem that provides random real-time read/write access to data in the Hadoop File System. One can store the data in HDFS either directly or through HBase. Data consumer reads/accesses the data in HDFS randomly using HBase. HBase sits on top of the Hadoop File System and provides read and write access.

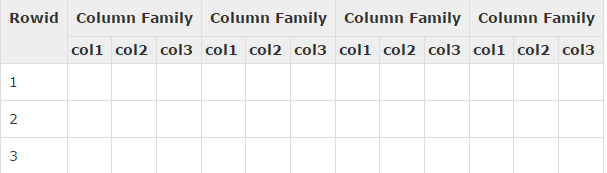
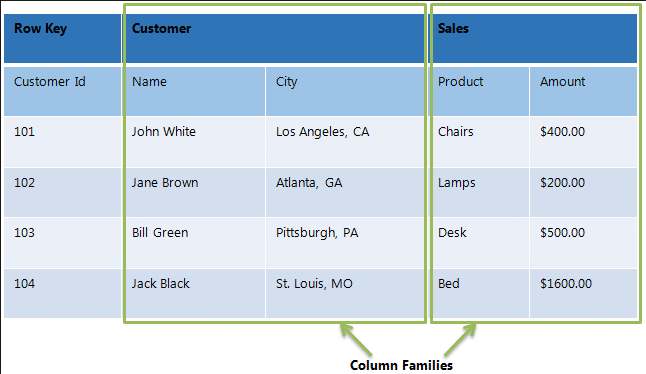
HBase is a column-oriented database and the tables in it are sorted by row. The table schema defines only column families, which are the key value pairs. A table have multiple column families and each column family can have any number of columns. Subsequent column values are stored contiguously on the disk. Each cell value of the table has a timestamp. In short, in an HBase:
- Table is a collection of rows.
- Row is a collection of column families.
- Column family is a collection of columns.
- Column is a collection of key value pairs.
E.g
Row-oriented data stores
- Data is stored and retrieved one row at a time and hence could read unnecessary data if only some of the data in a row is required.
- Easy to read and write records
- Well suited for OLTP systems
- Not efficient in performing operations applicable to the entire data set and hence aggregation is an expensive operation
- Typical compression mechanisms provide less effective results than those on column-oriented data stores
Column-oriented data stores
- Data is stored and retrieved in columns and hence can read only relevant data if only some data is required
- Read and Write are typically slower operations
- Well suited for OLAP systems
- Can efficiently perform operations applicable to the entire data set and hence enables aggregation over many rows and columns
- Permits high compression rates due to few distinct values in columns
Features of HBase
- Strictly consistent to read and write operations
- HBase is used extensively for random read and write operations
- HBase stores large amount of data in terms of tables
- Provides linear and modular scalability over cluster environment
- HBase is built for low latency operations
- Automatic and configurable sharding of tables
- Automatic fail-over supports between Region Servers
- Convenient base classes for backing Hadoop MapReduce jobs in HBase tables
- Easy to use Java API for client access
- Block cache and Bloom Filters for real-time queries
- Query predicate pushes down via server side filters.
Where to Use HBase
A table for a popular web application may consist of billions of rows. If we want to search particular row from such huge amount of data, HBase is the ideal choice as query fetch time in less. Most of the online analytics applications uses HBase. Traditional relational data models fail to meet performance requirements of very big databases. These performance and processing limitations can be overcomed by HBase.
Applications of HBase
- HBase is used whenever we need to provide fast random access to available data.
- HBase is used whenever there is a need to write heavy applications.
- Companies such as Facebook, Twitter, Yahoo, and Adobe use HBase internally.