Features of HDFS
1. Cost
The HDFS, in general, is deployed on a commodity hardware like your desktop/laptop which you use every day. So, it is very economical in terms of the cost of ownership of the project. Since, we are using low cost commodity hardware, you don’t need to spend huge amount of money for scaling out your Hadoop cluster. In other words, adding more nodes to your HDFS is cost effective.
2. Variety and Volume of Data
When we talk about HDFS then we talk about storing huge data i.e. Terabytes & petabytes of data and different kinds of data. So, you can store any type of data into HDFS, be it structured, unstructured or semi structured.
3. High Throughput
Throughput is the amount of work done in a unit time. Throughput talks about how fast you can access the data from the file system. Basically, it gives you an insight about the system performance. As you have seen in the above example where we used ten machines collectively to enhance computation. There we were able to reduce the processing time from 35 minutes to 3.5 minutes as all the machines were working in parallel. Therefore, by processing data in parallel, we decreased the processing time tremendously and thus, achieved high throughput.
4. Data Reliability
Data Replication is one of the most important and unique features of Hadoop HDFS. HDFS is a distributed file system which provides reliable data storage. HDFS can store data in the range of 100s of petabytes. It stores data reliably on a cluster of nodes. HDFS divides the data into blocks and these blocks are stored on nodes present in HDFS cluster. It stores data reliably by creating a replica of each and every block present on the nodes present in the cluster and hence provides fault tolerance facility. If node containing data goes down, then a user can easily access that data from the other nodes which contain a copy of same data in the HDFS cluster.
HDFS by default creates 3 copies of blocks containing data present in the nodes in HDFS cluster. Hence data is quickly available to the users and hence user does not face the problem of data loss. Hence HDFS is highly reliable.
5. Fault Tolerance
Issues in legacy systems
In legacy systems like RDBMS, all the read and write operation performed by the user, were done on a single machine. And if due to some unfavorable conditions like machine failure, RAM Crash, Hard-disk failure, power down, etc. the users have to wait until the issue is manually corrected. So, at the time of machine crashing or failure, the user cannot access their data until the issue in the machine gets recovered and becomes available for the user. Also, in legacy systems we can store data in the range of GBs only. So, in order to increase the data storage capacity, one has to buy a new server machine. Hence to store a huge amount of data one has to buy a number of server machines, due to which the cost becomes very expensive.
Fault tolerance achieved in Hadoop
Fault tolerance in HDFS refers to the working strength of a system in unfavorable conditions and how that system can handle such situations. HDFS is highly fault-tolerant, in HDFS data is divided into blocks and multiple copies of blocks are created on different machines in the cluster (this replica creation is configurable).
So whenever if any machine in the cluster goes down, then a client can easily access their data from the other machine which contains the same copy of data blocks. HDFS also maintains the replication factor by creating a replica of blocks of data on another rack. Hence if suddenly a machine fails, then a user can access data from other slaves present in another rack.
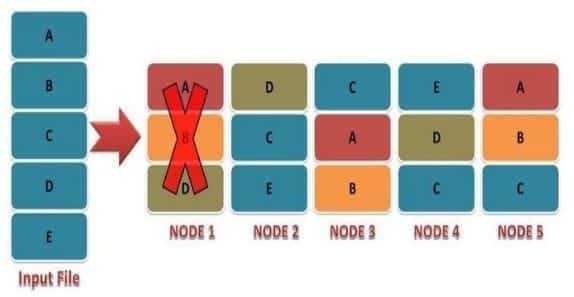
One simple Example
Suppose there is a user data named FILE. This data FILE is divided in into blocks say B1, B2, B3 and send to Master. Now master sends these blocks to the slaves say S1, S2, and S3. Now slaves create replica of these blocks to the other slaves present in the cluster say S4, S5 and S6. Hence multiple copies of blocks are created on slaves. Say S1 contains B1 and B2, S2 contains B2 and B3, S3 contains B3 and B1, S4 contains B2 and B3, S5 contains B3 and B1, S6 contains B1 and B2. Now if due to some reasons slave S4 gets crashed.
Hence data present in S4 was B2 and B3 become unavailable. But we don’t have to worry because we can get the blocks B2 and B3 from another slave S2. Hence in unfavorable conditions also our data doesn’t get lost. Hence HDFS is highly fault tolerant.
6. Data Integrity
Data Integrity talks about whether the data stored in my HDFS are correct or not. HDFS constantly checks the integrity of data stored against its checksum. If it finds any fault, it reports to the Name Node about it. Then, the Name Node creates additional new replicas and therefore deletes the corrupted copies.
7. Data Locality
Data locality talks about moving computation (processing unit) to data rather than the data to computation. In traditional system, we used to bring the data to the application layer and then process it. But now, because of the architecture and huge volume of the data, bringing the data to the application layer will reduce the network performance to a noticeable extent. So, in HDFS, we bring the computation part to the data nodes where the data is residing. Hence, you are not moving the data, you are bringing the program or processing part to the data.
8. Blocks
Blocks are the nothing but the smallest continuous location on your hard drive where data is stored. In general, in any of the File System, you store the data as a collection of blocks.
Similarly, Hadoop Distributed File System (HDFS) also stores the data in terms of blocks. However, the block size in HDFS is very large compare with other file system blocks because Hadoop works best with very large files. The default size of HDFS block is 64MB in Hadoop 1.x and 128MB in Hadoop 2.x. The files are split into 64MB/128MB blocks and then stored into the Hadoop filesystem. This value is configurable, and it can be customized. Using “dfs.block.size” parameter in hdfs-site.xml file you can configure your own block size. The Hadoop application is responsible for distributing the data block across multiple nodes.
We have to give block size in bytes in hdfs-site.xml
<property> <name>dfs.block.size<name> <value>134217728<value> // 134217728 bytes = 128 MB <property>
If the data size is less than the block size, then block size will be equal to the data size. For example, your file size is 400MB and suppose we are using the default configuration of block size 128MB. Then 4 blocks are created, the first 3 blocks will be of 128MB, but the last block will be of 16 MB size only instead of 128MB.
Why HDFS Blocks are Large in Size?
Whenever we talk about HDFS, we talk about huge data sets, i.e. Terabytes and Petabytes of data. So, if we had a block size of let’s say of 4 KB, as in Linux file system, we would be having too many blocks and therefore too much of the metadata. So, managing these no. of blocks and metadata will create huge overhead, which is something, we don’t want.
The main reason for having the HDFS blocks in large size is to reduce the cost of disk seek time. Disk seeks are generally expensive operations. Since Hadoop is designed to run over your entire data set, it is best to minimize seeks by using large files. In general, the seek time is 10ms and disk transfer rate is 100MB/s. To make the seek time 1% of the disk transfer rate, the block size should be 100MB. Hence to reduce the cost of disk seek time HDFS block default size is 64MB/128MB.
What should be the block size of Hadoop cluster?
An ideal Data Block size is based on several factors
- Size of Cluster
- Size of the input file
- Map task capacity
Actually, there is no such rule to keep block size is 64MB/128MB/256MB. Usually, it depends on the input data. If you want to maximize throughput for a very large input file, using very large blocks (may be 128MB or even 256MB) is best. But on the other hand, for smaller files using a smaller block size is better. So, here we are dealing with larger file large block & smaller file small blocks.
It’s recommended to use 128MB Size. For Larger Set Data means the huge amount of data sets and require enormous clusters of thousands of machines, and it’s recommended to use 256MB.
Advantages of HDFS Blocks
- The blocks are of fixed size, so it is very easy to calculate the number of blocks that can be stored on a disk.
- HDFS block concept simplifies the storage of the DataNodes. The DataNodes doesn’t need to concern about the blocks metadata data like file permissions etc. The NameNode maintains the metadata of all the blocks.
- If the size of the file is less than the HDFS block size, then the file does not occupy the complete block storage.
- As the file is chunked into blocks, it is easy to store a file that is larger than the disk size as the data blocks are distributed and stored on multiple nodes in a Hadoop cluster.
- Blocks are easy to replicate between the datanodes and thus provide fault tolerance and high availability of HDFS.
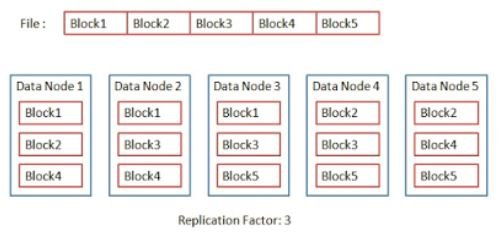
9. Replication
Replication factor is nothing but how many copies of your HDFS block should be copied (replicated) in Hadoop cluster. Using Replication factor, we can achieve Fault Tolerant and High Availability. Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of some of its components. Similarly, In Hadoop also when one DataNode is down, client access data without any interruption and loss. Because we have copy of same in another DataNode.
The default replication factor is 3 which can be configured as per our requirement. It can be changed to 2 (less than 3) or can be increased (more than 3).
Using “dfs.replication” in hdfs-site.xml file we can configure replication factor.
<property> <name>dfs.replication</name> <value>3</value> </property>
The ideal replication factor is considered to be 3. Because of following reasons,
To make HDFS Fault Tolerant we have to consider 2 cases
- DataNode failure
- Rack Failure
So, if one DataNode will down another copy will be available another DataNode. Suppose the 2nd Data Node also goes down but still that Data will be Highly Available as we still one copy of it stored onto different DataNode.
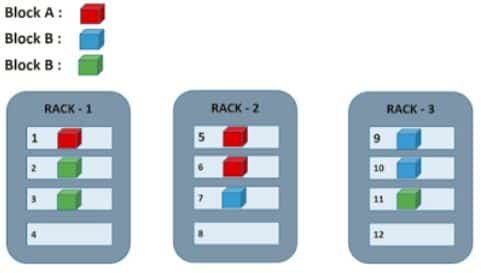
HDFS stores at least 1 replica to another Rack. So, in the case of entire Rack failure then you can get the data from the DataNode from another rack. Replication Factor also depends on Rack Awareness, which states the rule as “No more than one copy on the same node and no more than 2 copies in the same rack”, with this rule data remains highly available if the replication factor is 3. So, to achieve HDFS Fault Tolerant ideal replication factor is considered to be 3.
10. High Availability
Issues in legacy systems
- Data unavailable due to the crashing of a machine.
- Users have to wait for a long period of time to access their data, sometimes users have to wait for a particular period of time till the website becomes up.
- Due to unavailability of data, completion of many major projects at organizations gets extended for a long period of time and hence companies have to go through critical situations.
- Limited features and functionalities.
High Availability achieved in Hadoop
HDFS is a highly available file system, data gets replicated among the nodes in the HDFS cluster by creating a replica of the blocks on the other slaves present in HDFS cluster. Hence whenever a user wants to access his data, they can access their data from the slaves which contains its blocks and which is available on the nearest node in the cluster. And during unfavorable situations like a failure of a node, a user can easily access their data from the other nodes. Because duplicate copies of blocks which contain user data are created on the other nodes present in the HDFS cluster.
One simple Example
HDFS provides High availability of data. Whenever user requests for data access to the NameNode, then the NameNode searches for all the nodes in which that data is available. And then provides access to that data to the user from the node in which data was quickly available. While searching for data on all the nodes in the cluster, if NameNode finds some node to be dead, then without user knowledge NameNode redirects the user to the other node in which the same data is available. Without any interruption, data is made available to the user. So, in conditions of node failure also data is highly available to the users. Also, applications do not get affected because of any individual nodes failure.