Data Locality
Hadoop is specifically designed to solve Big Data Problems, so it will have to deal with larger amounts of data, so here it is not feasible to move such larger data sets towards computation. So, Hadoop provides this feature called as Data Locality.
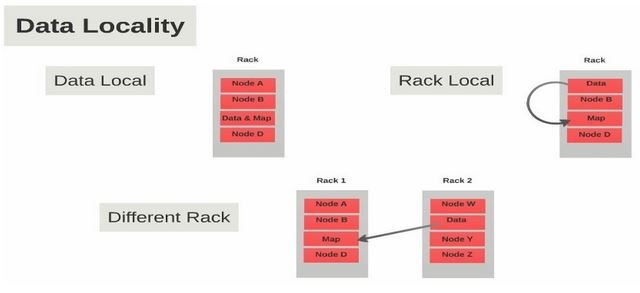
The major drawback of Hadoop was cross-switch network traffic due to the huge volume of data. To overcome this drawback, Data Locality came into the picture. Data locality refers to the ability to move the computation close to where the actual data resides on the node, instead of moving large data to computation. This minimizes network congestion and increases the overall throughput of the system.
In Hadoop, datasets are stored in HDFS. Datasets are divided into blocks and stored across the datanodes in Hadoop cluster. When a user runs the MapReduce job then NameNode sent this MapReduce code to the datanodes on which data is available related to MapReduce job.
Categories of Data locality in Hadoop.
Below are the various categories in which Hadoop Data Locality is categorized
1. Data local data locality in Hadoop
When the data is located on the same node as the mapper working on the data it is known as data local data locality. In this case, the proximity of data is very near to computation. This is the most preferred scenario.
2. Intra-Rack data locality in Hadoop
It is not always possible to execute the mapper on the same datanode due to resource constraints. In such case, it is preferred to run the mapper on the different node but on the same rack.
3. Inter-Rack data locality in Hadoop
Sometimes it is not possible to execute mapper on a different node in the same rack due to resource constraints. In such case, we will execute the mapper on the nodes on different racks. This is the least preferred scenario.