Hive Introduction
Apache Hive is a data warehousing tool in the Hadoop Ecosystem, which provides SQL like language for querying and analyzing Big Data.
What is Hadoop Ecosystem?
Hadoop Ecosystem is neither a programming language nor a service, it is a platform or framework which solves big data problems. You can consider it as a suite which encloses a number of services (ingesting, storing, analyzing and maintaining) inside it. Below are the Hadoop components, that together form a Hadoop ecosystem.
HDFS -> Hadoop Distributed File System YARN -> Yet Another Resource Negotiator MapReduce -> Data processing using programming Spark -> In-memory Data Processing PIG, HIVE-> Data Processing Services using Query (SQL-like) HBase -> NoSQL Database Mahout, Spark MLlib -> Machine Learning Apache Drill -> SQL on Hadoop Zookeeper -> Managing Cluster Oozie -> Job Scheduling Flume, Sqoop -> Data Ingesting Services Solr & Lucene -> Searching & Indexing Ambari -> Provision, Monitor and Maintain cluster
What is Apache Hive?
Apache Hive is an open source data warehouse system built on top of Hadoop for querying and analyzing large data sets stored in Hadoop files. Hive process structured and semi-structured data in Hadoop. Hive abstracts the complexity of Hadoop MapReduce. Initially, we have to write complex Map-Reduce jobs, but now with the help of Hive, you just need to submit merely SQL queries.
Hive is mainly targeted towards users who are comfortable with SQL. Hive use language called HiveQL (HQL) [Hive Query Language], which is similar to SQL. Internally, these queries or HQL gets converted to map reduce jobs by the Hive compiler. Therefore, we don’t need to worry about writing complex MapReduce programs to process your data using Hadoop. Apache Hive supports Data Definition Language (DDL), Data Manipulation Language (DML) and User Defined Functions (UDF). Hive abstracts the complexity of Hadoop. The main thing to notice is that there is no need to learn java for Hive.
The Hive generally runs on your workstation and converts your SQL query into a series of jobs for execution on a Hadoop cluster. Apache Hive organizes data into tables.
SQL + Hadoop MapReduce = HiveQL
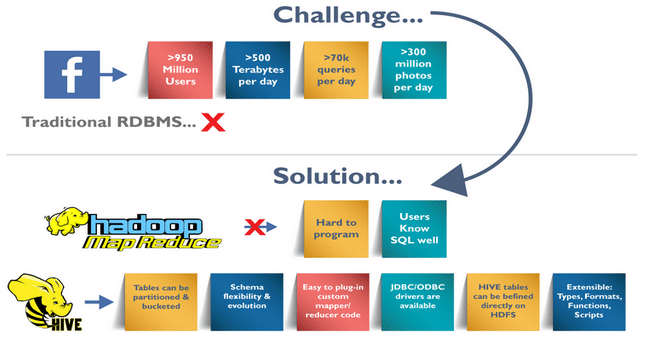
Challenges at Facebook: Exponential Growth of Data
Before 2008, all the data processing infrastructure in Facebook was built around a data warehouse based on commercial RDBMS. These infrastructures were capable enough to suffice the needs of Facebook at that time. But, as the data started growing very fast, it became a huge challenge to manage and process this huge dataset. According to a Facebook article, the data scaled from a 15 TB data set in 2007 to a 2 PB data in 2009. Also, many Facebook products involve analysis of the data like Audience Insights, Facebook Lexicon, Facebook Ads, etc. So, they needed a scalable and economical solution to cope up with this very problem and, therefore started using the Hadoop framework.
Introducing Hadoop – MapReduce
But, as the data grew, the complexity of Map-Reduce codes grew proportionally. So, training people with a non-programming background to write MapReduce programs became difficult. Also, for performing simple analysis one has to write a hundred lines of MapReduce code. Since, SQL was widely used by engineers and analysts, including Facebook, therefore, putting SQL on the top of Hadoop seemed a logical way to make Hadoop accessible to users with SQL background.
Hence, the ability of SQL to suffice for most of the analytic requirements and the scalability of Hadoop gave birth to Apache Hive that allows to perform SQL like queries on the data present in HDFS. Later, the Hive project was open sourced in August’ 2008 by Facebook and is freely available as Apache Hive today.
History of Hive
Data Infrastructure Team at Facebook developed Hive. Apache Hive is also one of the technologies that are being used to address the requirements at Facebook. It is very popular with all the users internally at Facebook. It is being used to run thousands of jobs on the cluster with hundreds of users, for a wide variety of applications.
Apache Hive-Hadoop cluster at Facebook stores more than 2PB of raw data. It regularly loads 15 TB of data on a daily basis. Now it is being used and developed by a number of companies like Amazon, IBM, Yahoo, Netflix, Financial Industry Regulatory Authority (FINRA) and many others.
Facebook had faced a lot of challenges before implementation of Apache Hive. Challenges like the size of data being generated increased or exploded, making it very difficult to handle them. The traditional RDBMS could not handle the pressure. As a result, Facebook was looking out for better options. To overcome this problem, Facebook initially tried using MapReduce. But it has difficulty in programming and mandatory knowledge in SQL, making it an impractical solution. Hence, Apache Hive allowed them to overcome the challenges they were facing. With Apache Hive, they are now able to perform the following:
- Schema flexibility and evolution
- Tables can be portioned and bucketed
- Apache Hive tables are defined directly in the HDFS
- JDBC/ODBC drivers are available
Apache Hive saves developers from writing complex Hadoop MapReduce jobs for ad-hoc requirements. Hence, hive provides summarization, analysis, and query of data. Hive is very fast and scalable. It is highly extensible. Since Apache Hive is similar to SQL, hence it becomes very easy for the SQL developers to learn and implement Hive Queries.
Hive reduces the complexity of MapReduce by providing an interface where the user can submit SQL queries. So, now business analysts can play with Big Data using Apache Hive and generate insights. It also provides file access on various data stores like HDFS and HBase. The most important feature of Apache Hive is that to learn Hive we don’t have to learn Java.