HDFS Federation
Hadoop Distributed File System – HDFS is the world’s most reliable storage system. HDFS is a File System of Hadoop designed for storing very large files.
HDFS architecture follows master/slave topology. In which master is NameNode and slaves is DataNode. Namenode stores meta-data i.e. number of blocks, their location, replicas. This meta-data is available in memory in the master for faster retrieval of data. NameNode maintains and manages the slave nodes, and assigns tasks to them.
HDFS Federation enhances an existing HDFS architecture. In prior HDFS architecture for entire cluster allows only single namespace. In that configuration, Single NameNode manages namespace. If NameNode fails, the cluster as a whole would be out of services. The cluster will be unavailable until the NameNode restarts or brought on a separate machine. Federation overcomes this limitation by adding support for many NameNode/Namespaces to HDFS.
Current HDFS Architecture
Hadoop HDFS has 2 main layers
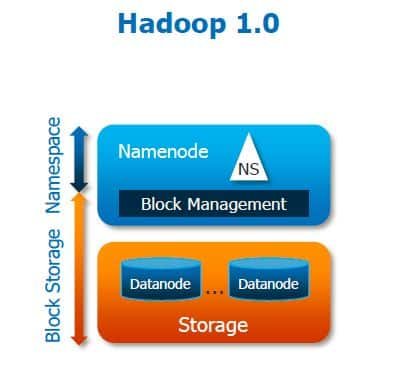
As you can see in the above figure, the current HDFS has 2 layers
1. HDFS Namespace (NS): This layer is responsible for managing the directories, files and blocks. This layer supports the basic file system operations e.g. listing of files, creation of files, modification of files and deletion of files and folders.
2. Storage Layer : It comprises two basic components.
1. Block Management
It performs the following operations:
1. Checks heartbeats of DataNodes periodically and it manages DataNode membership to the cluster.
2. Manages the block reports and maintains block location.
3. Supports block operations like creation, modification, deletion and allocation of block location.
4. Maintains replication factor consistent throughout the cluster.
2. Physical Storage
It is managed by DataNodes which are responsible for storing data and thereby provides Read/Write access to the data stored in HDFS.
So, the current HDFS Architecture allows you to have a single namespace for a cluster. In this architecture, a single NameNode is responsible for managing the namespace. This architecture is very convenient and easy to implement. Also, it provides sufficient capability to cater the needs of the small production cluster.
Limitations of current HDFS Architecture
1. Tightly coupled block storage and Namespace
Namespace layer and storage layer are tightly coupled. It makes alternate implementation of namenode difficult. And it restricts other services to use block storage directly.
2. Namespace Scalability
The namespace is not scalable like DataNode. Scaling in HDFS cluster is horizontally by adding DataNodes. But we can’t add more namespace to an existing cluster. We can scale namespace vertically on a single NameNode.
3. Performance
Hadoop entire performance depends on the throughput of the namenode. An operation of current file system depends on the throughput of a single namenode. NameNode at present supports 60,000 concurrent tasks. Upcoming MapReduce will have support for more than 1,00,000 concurrent tasks. And this will need more namenode.
4. Isolation
Many of the organizations (vendor) having HDFS deployment, allows multiple organizations (tenant) to use their cluster namespace. So, there is no separation of namespace and therefore, there is no isolation among tenant organization that are using the cluster.
5. Memory
The NameNode stores the entire namespace in RAM for fast access. This leads to limitations in terms of memory size i.e. The number of namespace objects (files and blocks) that a single namespace server can cope up with.
HDFS Federation Architecture
1. In HDFS Federation Architecture, we have horizontal scalability of name service. Therefore, we have multiple NameNodes which are federated, i.e. Independent from each other.
2. The DataNodes are present at the bottom i.e. Underlying storage layer.
3. Each DataNode registers with all the NameNodes in the cluster.
4. The DataNodes transmit periodic heartbeats, block reports and handles commands from the NameNodes
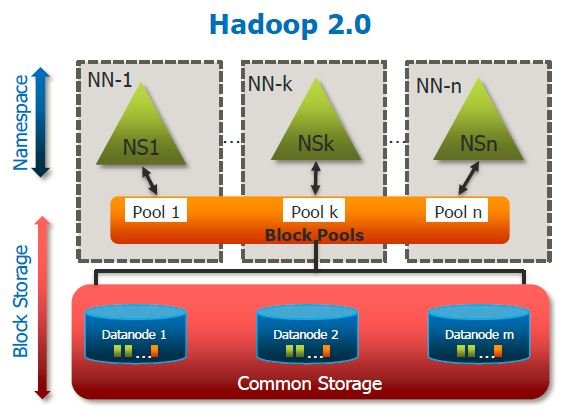
1. There are multiple namespaces (NS1, NS2,…, NSn) and each of them is managed by its respective NameNode.
2. Each namespace has its own block pool (NS1 has Pool 1, NSk has Pool k and so on).
3. As shown in the image, the blocks from pool 1 are stored on DataNode 1, DataNode 2 and so on. Similarly, all the blocks from each block pool will reside on all the DataNodes.
1. Block Pool
Set of blocks is Block pool that belongs to a single namespace. There is a collection of pools in HDFS federation architecture. And each block is managed independently from other. This allows a namespace to create Block ID for new blocks without coordination with another namespace. All Datanodes stores data blocks present in all block pool.
2. Namespace volume
Namespace along with its block pool is Namespace volume. Many namespace volumes are there in HDFS federation. Each namespace volume works independently. When we delete namenode or namespace, then corresponding block pool present on the datanodes will also be deleted.
Benefits of HDFS Federation
HDFS Federation overcomes the limitations of prior HDFS architecture. Hence it provides:
1. Isolation
There is no isolation in single namenode in a multi-user environment. In HDFS federation different categories of application and users can be isolated to different namespaces by using many namenodes.
2. Namespace Scalability
In federation many namenodes horizontally scales up in the filesystem namespace.
3. Performance
We can improve Read/write operation throughput by adding more namenodes.
Summary
HDFS federation has been introduced to overcome the limitations of earlier HDFS implementation. Adding scalability at the namespace layer is the most important feature of HDFS federation architecture. But HDFS federation is also backward compatible, so the single namenode configuration will also work without any changes. Let us summarize our discussion.
- HDFS federation separates the namenode layer and the storage layer.
- HDFS federation is designed to overcome the limitations of the single node HDFS architecture where the storage can scale up horizontally not the namespace.
- HDFS federation comes up with following advantages –
- Isolation
- Scalability
- Performance
- HDFS configuration is very simple and is also easy to manage.